Python Web Scraper: 2024 Walkthrough, Examples, and Expert Tips
Python provides powerful tools for scraping data from the internet. This guide walks you through everything you need to know to get started.
 February 10, 2024
February 10, 2024 16 minute reading
16 minute reading
The internet is enormous. Statista predicts that the data captured and consumed online will reach 181 zettabytes by 2025. How big is a zettabyte? One zettabyte can store 30 billion 4K movies or 7.5 trillion songs. If you wanted to keep one zettabyte at home, you’d need 100 million hard drives of 10 terabytes each.
Not all of that data is useful. However, it’s a goldmine of information that businesses can tap into to improve marketing, study competitors, keep track of prices, and perform countless other tasks that depend on accurate real-time data.
The primary question is how to do it. It’d be impossible for anyone to manually find and capture all the data they needed from that vast trove. Even if possible, it’d take so long that the data would be useless by the time you get it into a data analysis tool.
Web scraping—parsing HTML web pages or other formatted text to extract data—is a popular solution used by companies of all sizes to solve this.
Hire an expert python programmer on Fiverr
Business use cases for web scraping
Lee Foot, a freelance SEO consultant and owner of the Welding & Welder e-commerce site, tells Fiverr that he frequently writes and uses Python Web scrapers for his day-to-day work. Some of the things Lee uses Python web scraping for include:
Scraping supplier sites for new products, stock status, and price changes.
Scraping Google search results to see if page titles are being re-written.
Scraping competitor prices.
Scraping Google shopping results to benchmark price and positioning.
Scraping competitor sitemaps to monitor for new pages.
Why use Python for web scraping?
Python contains powerful libraries that encapsulate much of the web scraping process so that you can focus primarily on the functionality.
Python's beginner-friendly syntax and readability also make it a powerful choice for web scraping. Whereas many other programming languages, such as C# and Java, contain extensive libraries for parsing content and scraping data, Python code is more readable, easier to understand, and suits beginners and professionals.
Lee Foot says, “The biggest tip is to throw yourself into the deep end. There are excellent Python libraries out there that can assist, such as AdverTools, BeautifulSoup, and Python Requests.”
Because of Python’s immense popularity, open-source projects continue to grow, making it easy to find open-source code that does what you need in your web scraping project. For more advanced Python functionality, buy Python programming services from Fiverr experts to help you.
Web scraping terminology
Even if you’re already familiar with web scraping basics and terms such as “XML,” “JSON,” and “parsing,” this section is still important. All advanced web scraping tools build on these fundamentals, so it’s vital to understand them completely.
We won’t, however, go into a full-scale Python tutorial. If you want to learn Python, check out our article on writing code with ChatGPT. You can also buy online coding lessons from Fiverr freelancers to learn Python.
If you prefer to hire a programmer to create the web scraper, it’s still important to understand the basics of web scraping to provide comprehensive instructions for the programmer.
How websites display their data
All websites display their data in HTML—HyperText Markup Language. HTML code is plain text that browsers such as Chrome, Firefox, and Safari convert into visual elements.
Google search results for the query “cat.”
Using a Chrome extension called Web Developer, we can highlight some of the HTML elements in the above page, making the page’s structure more apparent.
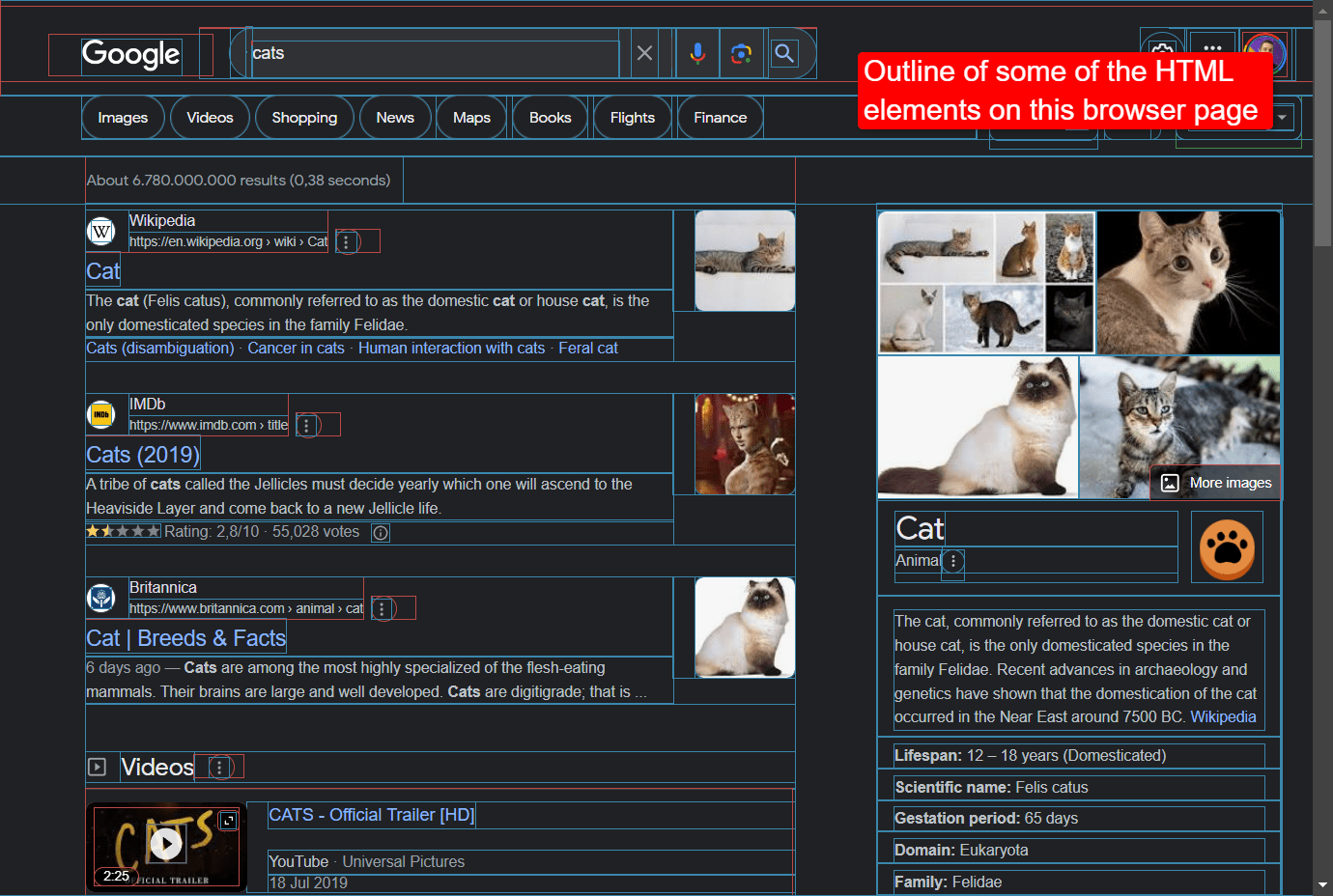
Image showing the outlines of some HTML elements that make up this page.
However, we see nothing like the image above when we look at the underlying HTML content. In the screenshot below, the text for the first result—Wikipedia—is buried within HTML tags and hard to detect. Making matters worse, the underlying HTML also contains JavaScript source code.
JavaScript is a front-end programming language that executes code in the browser. Developers use JavaScript to make web pages dynamic and to load them faster.
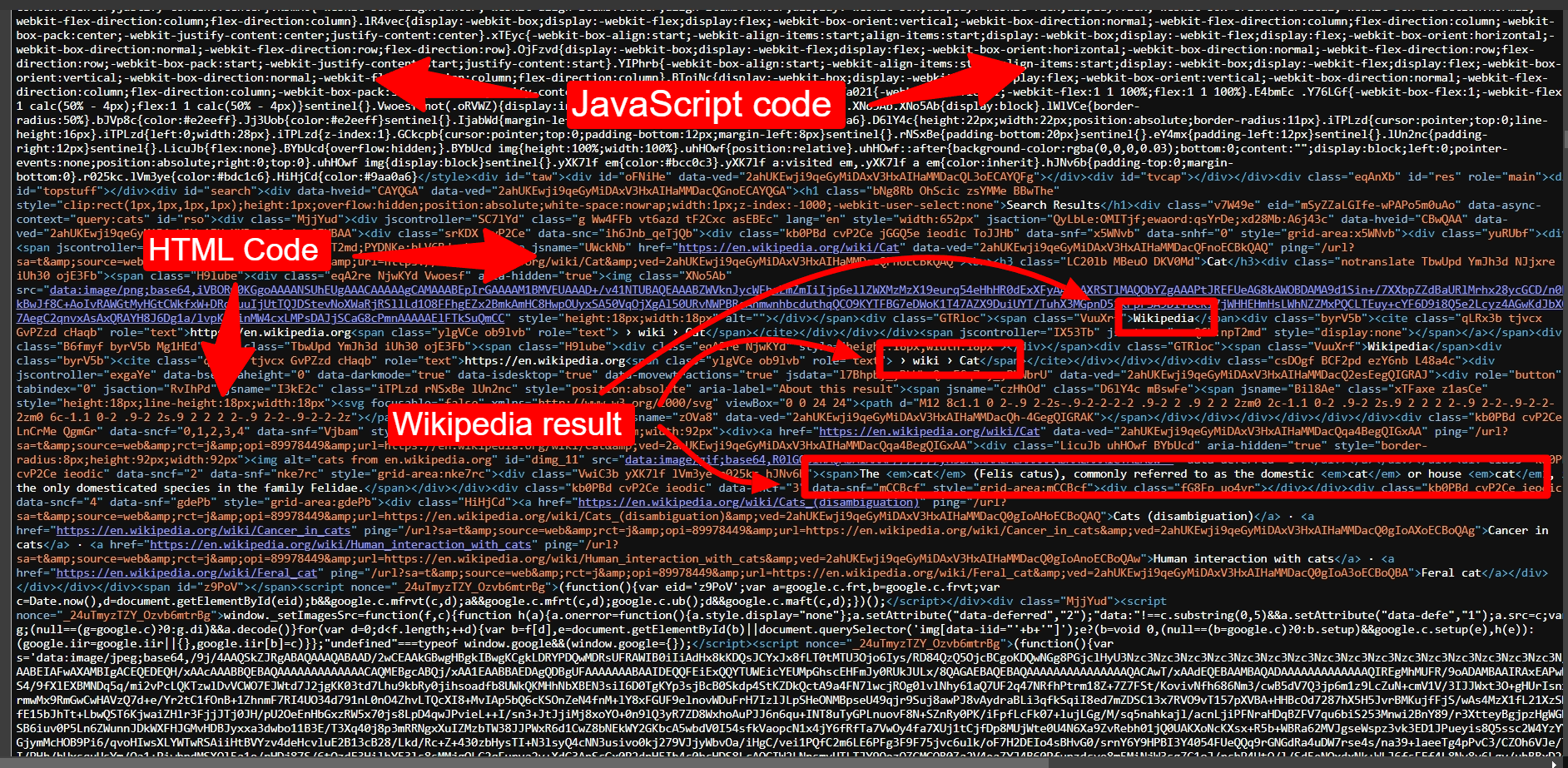
Underlying HTML content for the Google search results page above.
Although the page looks simple visually, its underlying structure is far more complex, so we must use an HTML parser to find the data we need.
“Parsing” means to break text into meaningful parts. HTML consists of “tags”—special keywords in angle brackets that describe how the browser must treat that text.
For example, to define a new paragraph in HTML, place the text inside a “<p></p>” tag or a “<div></div>” tag.
When the browser sees a “<p></p>” combination, it knows to display that text in a different paragraph, even if the underlying HTML has it on the same line.
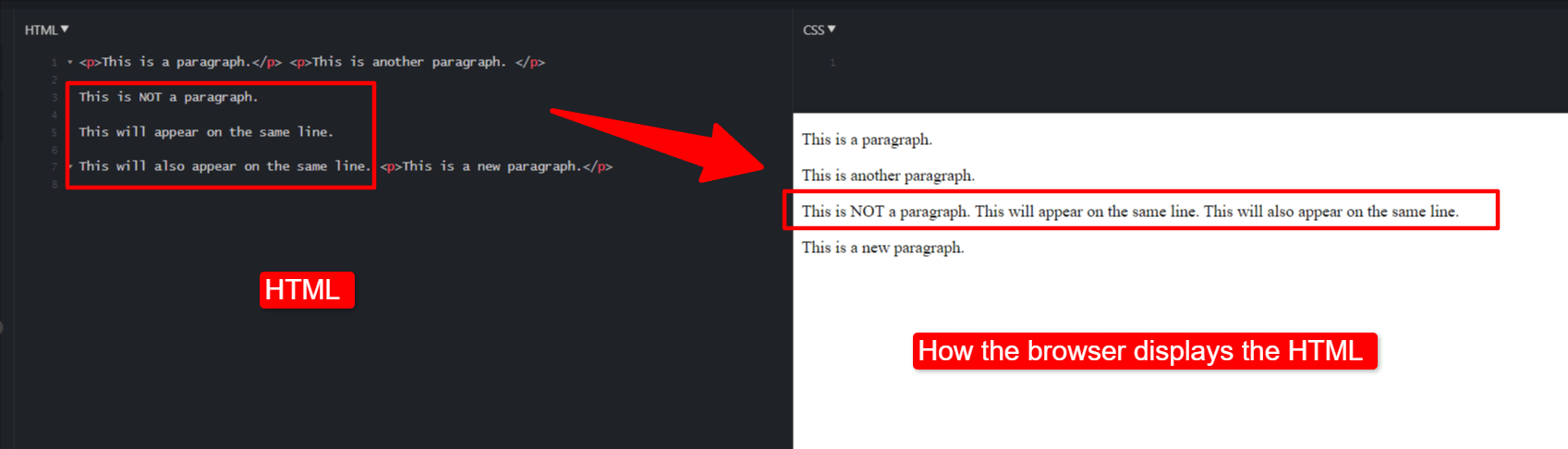
Code showing how HTML renders on a browser.
HTML tags can also have attributes that contain valuable data for scraping. For example, the way to make a link in HTML is to use the “<a>” or “anchor” tag. The anchor tag has an attribute called “href” (short for “hypertext reference”), which specifies the link itself, as shown in the code snippet below.
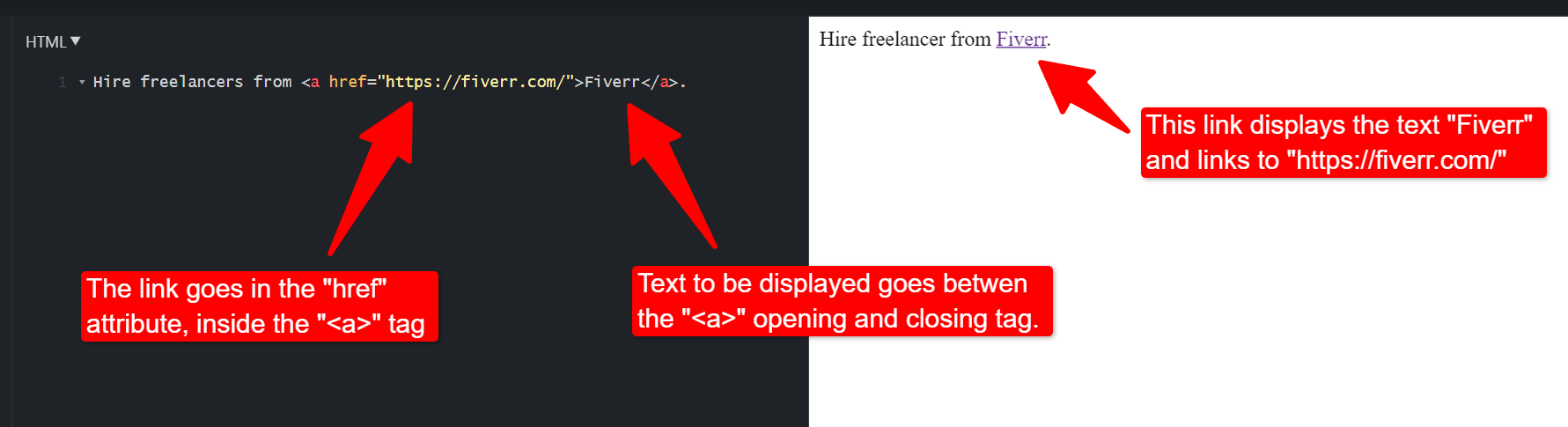
HTML anchor tag.
Similarly, many other attributes and HTML tags provide immense data that can be useful. Advanced tags and attributes can represent company names, postal and physical addresses, telephone numbers, image descriptions, file locations, bullet points, and headings.
Other data formats
HTML isn’t the only data format on the web.
XML—eXtensible Markup Language—is a data-aware text format. Using XML, it’s possible to give raw data structure to define meaningful objects inside textual data. For example, the following XML code defines a company.
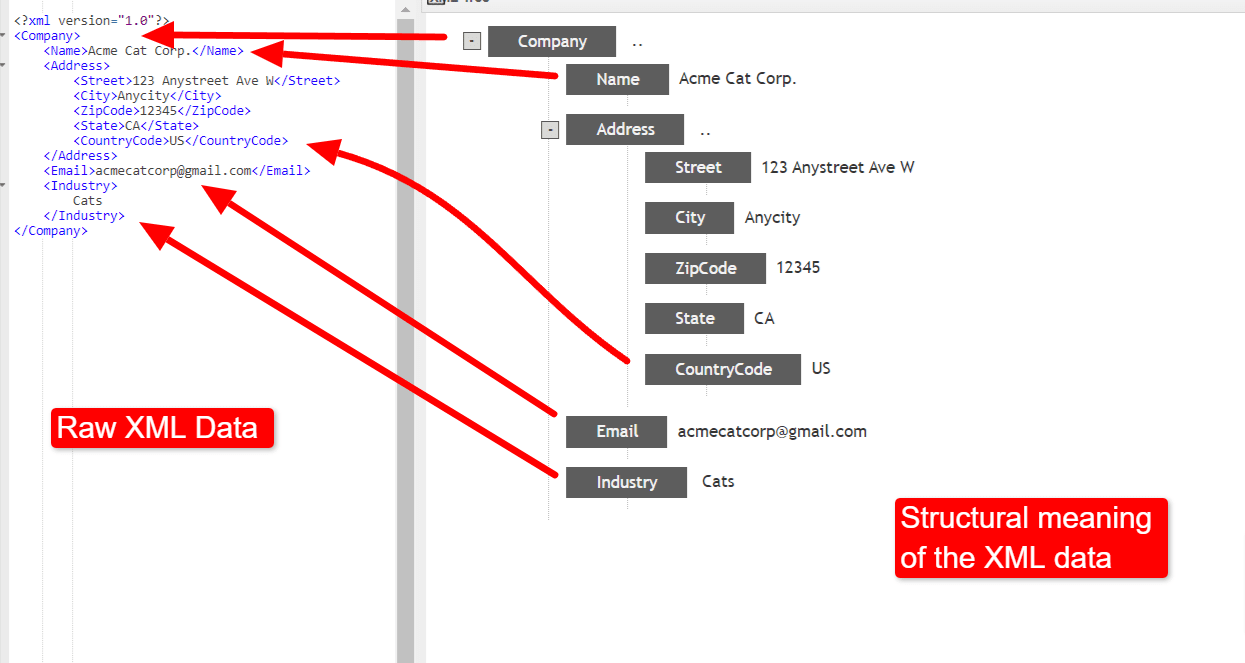
XML data representing a company entity, taken from Tutorials Point.
XML’s data-aware nature and rigorous syntax make it an ideal web scraping data source.
JSON is another data-aware text format that uses syntax that’s vastly different from XML. JSON stands for JavaScript Simple Object Notation, a text format that attempts to define objects using a familiar JavaScript syntax.
Like XML, JSON data is structured and meaningful, making it an ideal data source for web scraping. Converting the above XML code to JSON looks as follows:
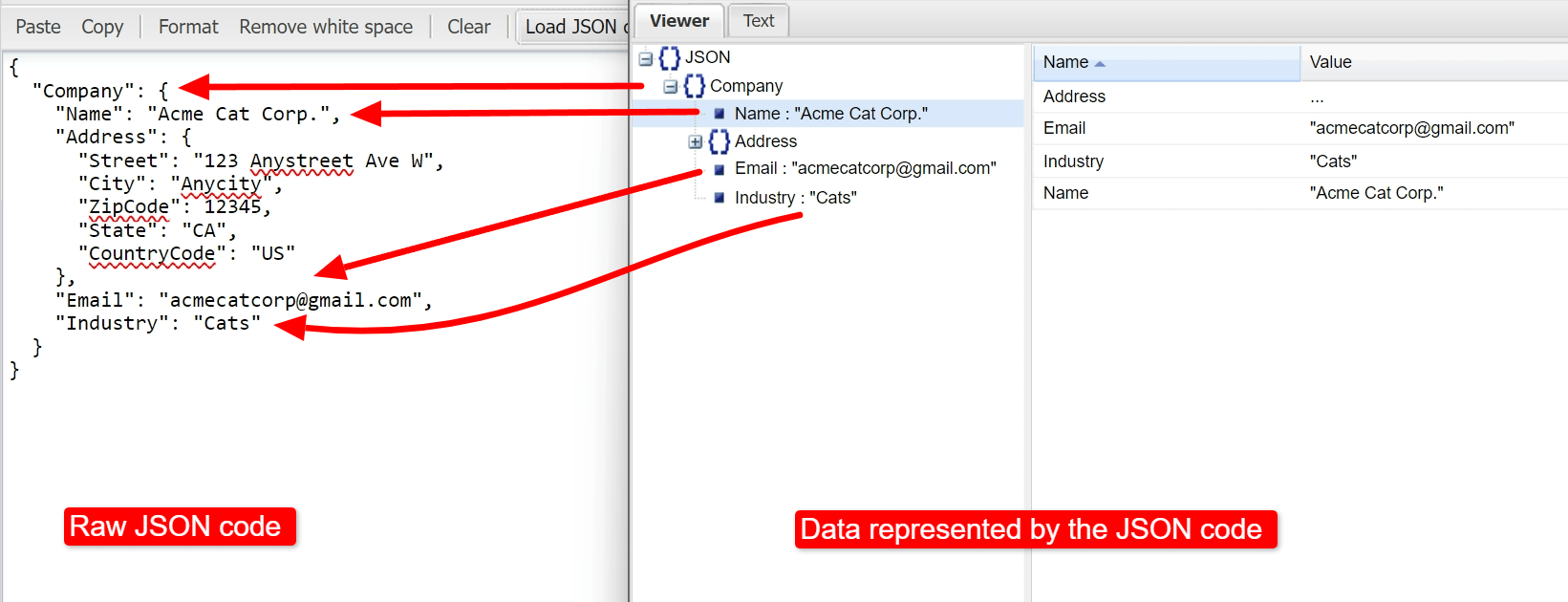
JSON Code, from JSON Viewer.
CSV files are another popular source of structured data that you can scrape. PDFs are more challenging to scrape because Adobe created the PDF format as a visual file format, not a data-aware one. The ability to scrape data from a PDF depends on how that specific PDF file is structured.
Character encoding and web scraping
Another important concept to grasp when scraping web pages is character encoding.
Computers store numbers, not letters. Every character you see on a computer screen is stored as a number in your computer’s memory. Your operating system or web browser translates those numbers into text and displays them to you. When computers first appeared, only 128 numbers existed (“code points”) to represent every character in the standard English language. The mapping of numbers to characters using this system falls under the name ASCII—the American Standard Code for Information Interchange.
Unfortunately, 128 code points could only represent English characters and a handful of other languages. In response, the ASCII system grew from 128 code points to 256, called Extended ASCII.
Using Extended ASCII’s 256-character limit, computers could now represent many more languages. Each language has a corresponding “character encoding,” which maps ASCII code points to characters. For example, ASCII code point 224 can represent different characters depending on the encoding chosen, as shown in the lines of code below.
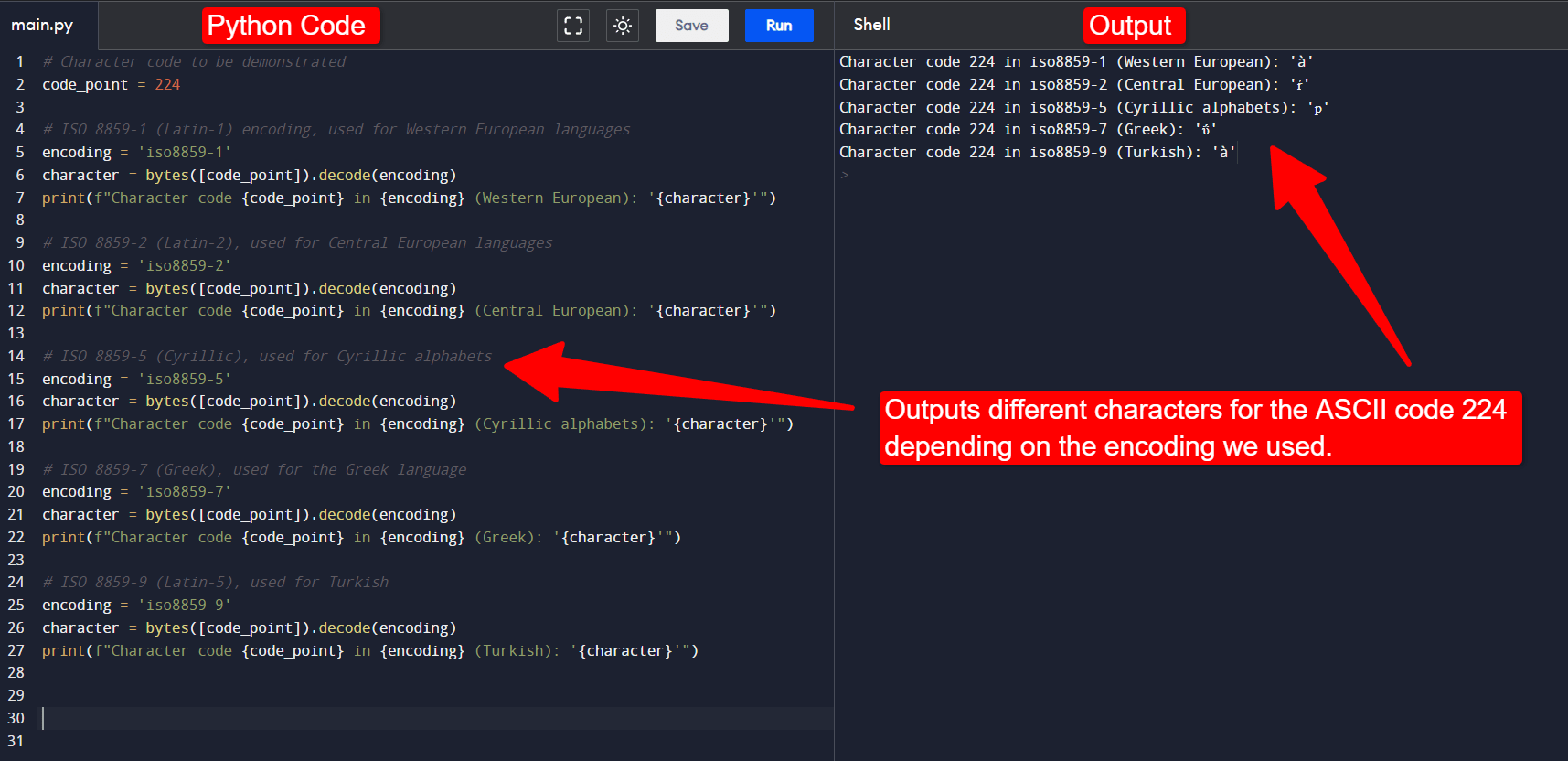
Python code demonstrating how setting a different encoding results in outputting different characters even though the underlying number (224) is the same.
The Extended ASCII system failed to account for many European and Asian languages. In 1991, the Unicode Consortium introduced a new standard called Unicode, which aimed to represent all characters for all languages in a single encoding.
An encoding called “UTF-8” arose from that standard. UTF-8 has become the dominant character encoding used on the web because it’s backward compatible with ASCII. Moving forward, this makes encoding much simpler. However, many legacy websites still use pre-UTF-8 encoding.
Understanding character encoding is vital for successful web scraping. If your code only supports ASCII-128 encoding, but you’re trying to scrape a website that uses a Western European language encoding (ASCII 256, matched to the corresponding encoding), you’ll end up with garbled data. In the image below, we used a Western European encoding to create the German characters on the left, but we read the file using a different encoding on the right. The result is garbled, useless data.

Image showing garbled data when using the wrong encoding to read a file.
Your Python web scraper must detect the encoding correctly to capture the correct character data.
Converting text data from one encoding to another is a fairly advanced topic, and you might need to buy Python programming services to help you. Fortunately, most modern web pages use UTF-8 now, which Python supports natively.
Requests and responses
Another core concept of web scraping projects is HTTP requests and responses.
HTTP stands for Hypertext Transfer Protocol, the protocol for transferring data on the World Wide Web.
Your browser initiates an HTTP request to a server whenever it visits a web address. The server then issues a response that includes an HTTP status code. Many HTTP status codes exist to provide information to the requester. For example, a 200 code means the request succeeded; 404 means the resource wasn’t found on that server; and 500 means the server had an internal error.
Browsers aren’t the only tools that can send HTTP requests. Any tool requiring data from a server must send a properly formatted request.
Each request contains “HTTP headers”—name-value pairs with data that helps the server understand the nature of the request. For example, the “User-Agent” header tells the server what type of device or browser is making the request, such as an iPhone, Chrome desktop browser, or the name of your Python automation tool. The browser can then decide what type of HTML document to send as a response. For mobile device user agents, it might send a more straightforward version and compressed images to make the load time faster.
A lot happens under the hood when requesting and reading web server responses. Manually coding HTTP request headers and how to handle all types of status codes can be a tedious and time-consuming task.
The third-party Python Requests library handles many of these tasks automatically, freeing programmers to focus on the web scraping part.
To install this Python library, run the following command in your terminal (Linux) or command prompt (Windows):
pip install requests
The following code sample demonstrates how easy it is to handle HTTP requests and responses in Python 3 (Python’s latest major version) using the Python Requests library.
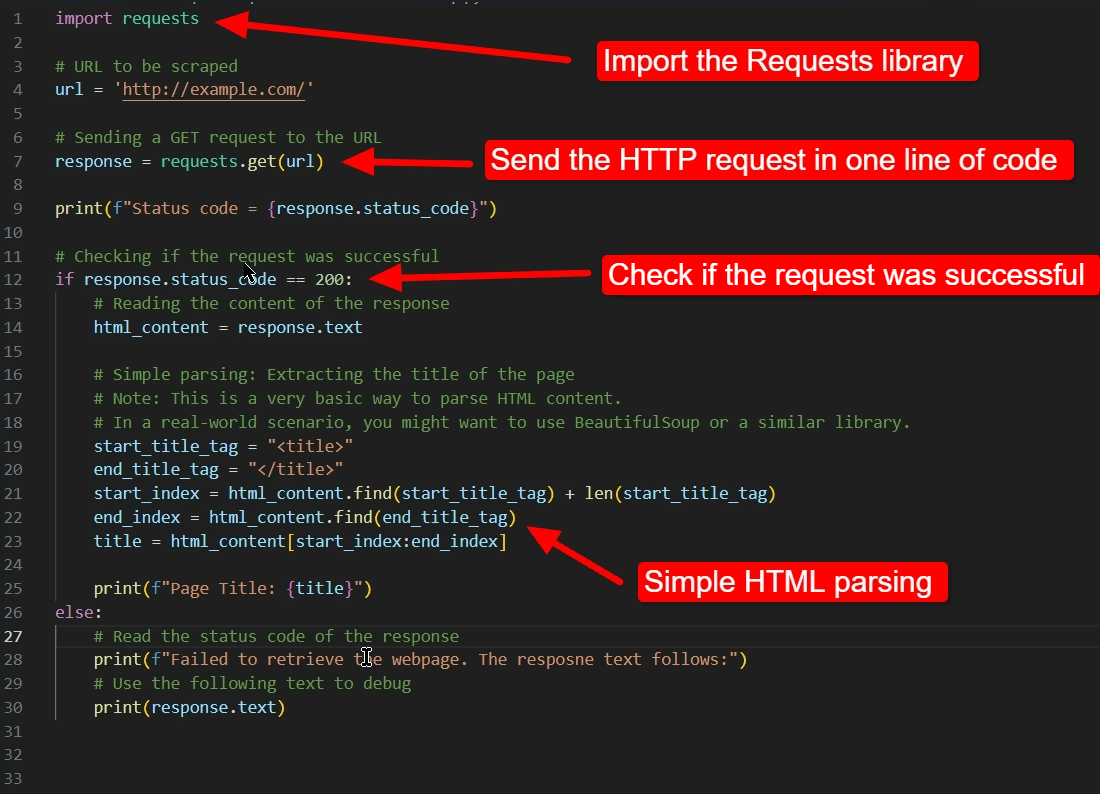
Sample code demonstrating the HTTP Requests library.
To parse HTML, you’d typically use a library like BeautifulSoup, which has far more advanced functionality. In the above code sample, we’re mainly interested in how the request and response cycle goes.
We begin the code by importing the requests library with the following command:
import requests
Once we’ve imported the library, we only need to provide a URL and then call the following line to perform all the necessary actions to get data from the server:
response = requests.get(url)
The “response” variable now contains a “response“ object, with properties and methods such as:
response.text: Returns the content of the response, in Unicode.
response.content: Returns the content of the response in bytes.
response.status_code: Returns the status code of the response.
response.headers: Returns the response headers.
response.cookies: Returns any cookies sent by the server.
response.encoding: Returns the encoding used to decode response.text.
response.json(): This method returns the response content as a JSON object (Python dictionary). It’s commonly used for API (Application Program Interface) responses.
response.close(): This method releases the network resources associated with the response. It’s essential to free up system resources, especially when dealing with many requests during web scraping.
On line 12, we check if the response status code equals 200. If the line equates to “True,” we proceed with parsing the response.
The response object also has a “response.ok” property, which checks if the status code is less than 400. Response codes in the 400 range represent client errors, such as a wrong URL (404) or lack of permissions to access that resource (403). Response codes in the 500 range represent server errors, such as 500 for any generic error on the server’s side or 503 when the server is unavailable.
In our code sample, we check response.status_code because the other response codes in the below-400 range often require special handling, whereas 200 signifies that the response contains the full content of what you requested.
To learn more about what some of the response’s dictionary properties contain, such as headers and cookies, iterate through their contents using the following code:
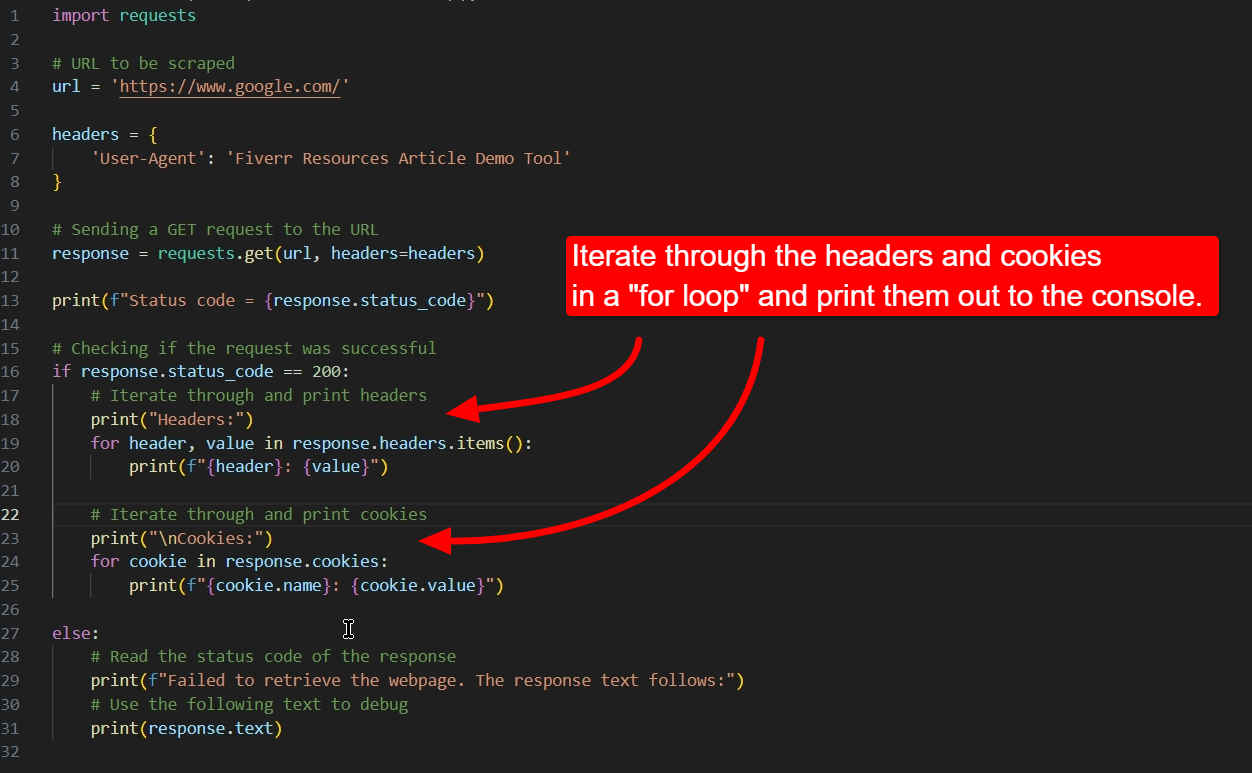
Python code for iterating through headers and cookies in a response.
Web scraping step-by-step
Regardless of what programming language or tool you use to scrape website data, the following are the main steps for every web scraping activity:
Decide what data you need.
Check if the data is available publicly through an API or official source. It’s far easier to collect data from official, well-structured sources than scraping it.
If that official data isn’t available, examine the format and structure of each data source you want to scrape. Is it in HTML, XML, JSON, CSV, or PDF? If it’s in HTML, determine if it has a predictable structure or “data attributes” to help a machine understand the semantics.
Write a script or tool to fetch the data through an HTTP request. The script will likely need to account for security checks and errors from servers that prevent malicious access to their sites. Although web scraping for legitimate, ethical purposes is often not illegal, this kind of scraping uses the same techniques that bad actors use for nefarious purposes. To prevent bad actors from running malicious robots on their websites, many website owners implement checks to avoid this. These checks might include blocking specific IP addresses or proxies from accessing their site, or implementing “Are you Human?” checkboxes on the web page before you can access it. Getting around these restrictions can be challenging, and you might want to buy programming services from a Fiverr freelancer to help you.
Parse the response to find elements on the page containing the needed data.
Save the data in a data store (such as a database).
Scraping typically happens over many web pages, so your tool will likely include a feature to follow links or read URLs from a list using a Python automation solution.
Once you have the data in a database, perform data science operations using machine learning and AI to extract meaning from the data. If you need help doing this, buy data processing services from Fiverr freelancers to help you.
How to find elements in HTML, XML, JSON, etc.
Parsing XML or JSON is far simpler than parsing HTML because XML and JSON are data-aware.
A purpose-built query language called XPath exists to query XML easily. The language provides methods for accessing specific data directly, no matter how deeply buried it is in the XML.
Querying HTML to extract data can be far more challenging. Unlike XML, HTML doesn’t enforce rigorous standards. For example, HTML tags don’t always require a matching closing tag. Both of the following HTML code snippets are valid HTML:
Snippet #1:
<p>This is a paragraph. <p>This is another paragraph. <p>This is the third paragraph.
Snippet #2
<p>This is a paragraph.</p> <p>This is another paragraph.</p> <p>This is the third paragraph.</p>
Even though the first snippet doesn’t contain the closing </p> tag, it still displays correctly in a browser.
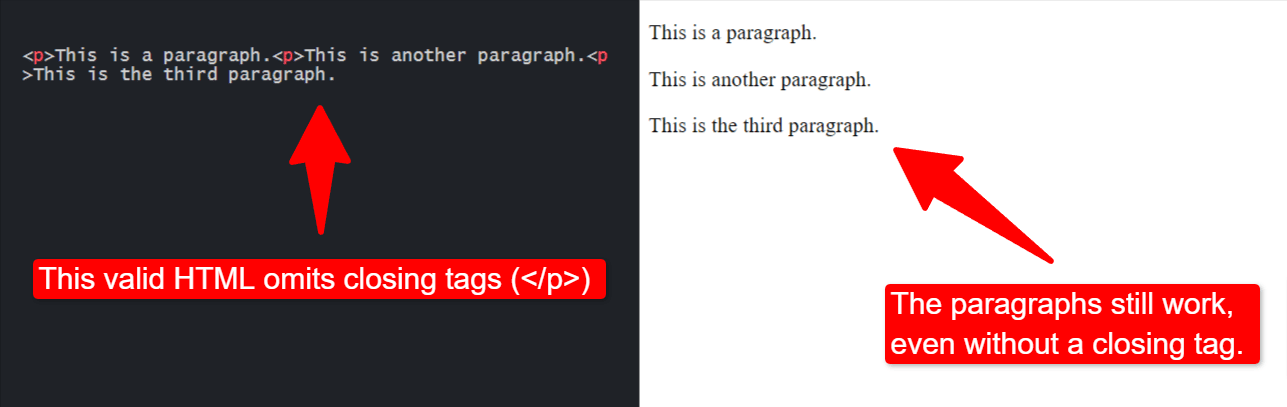
Code snippet of HTML “p” tags without a closing tag.
Furthermore, HTML is often “broken”—containing errors that browsers must somehow deal with, such as missing attributes or including HTML tags where they don’t belong.
The combination of broken HTML with non-rigorous standards makes extracting data from HTML extremely challenging.
Fortunately, various libraries exist to simplify this. One popular Python library is lxml, a Python wrapper for the robust libxml2 and libxslt libraries, which are written in C. Lxml supports directly querying XML through XPath and can also handle broken HTML to a degree.
Finding elements through CSS selectors and class names
Web developers style web pages using CSS. CSS selectors are the first part of a CSS (Cascading Style Sheet) instruction. For example, in the following CSS, which changes all H1 (Heading 1) tags to blue, the “h1” part is the CSS Selector.
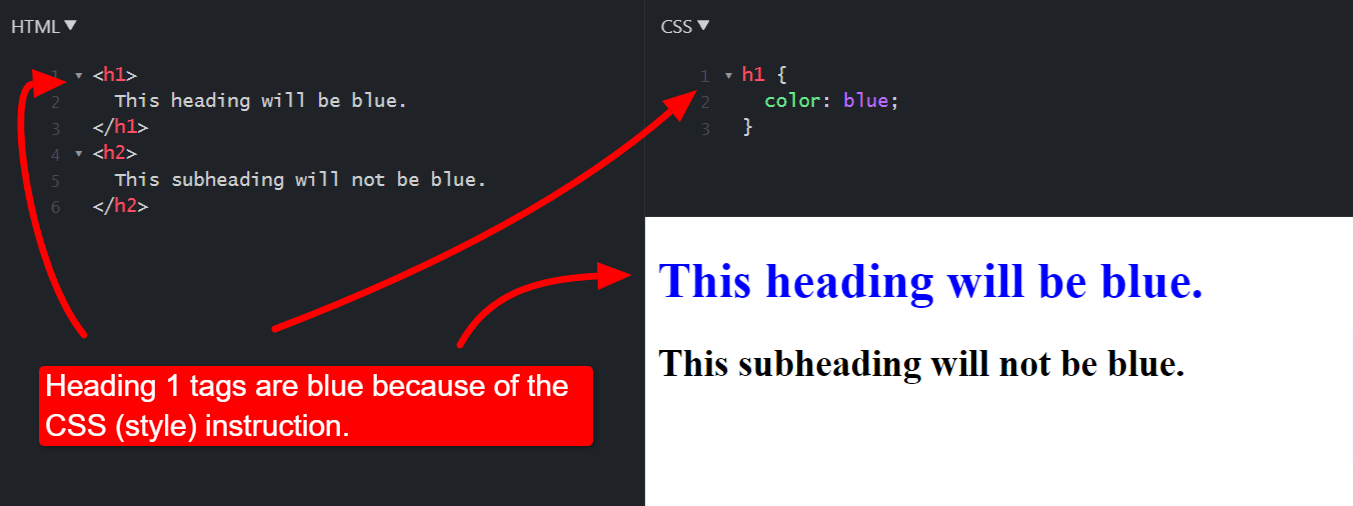
HTML and CSS code demonstrating CSS selectors.
CSS selectors can be pretty complex, including combinations of class names, nested tags, and attributes to precisely style specific elements on a web page.
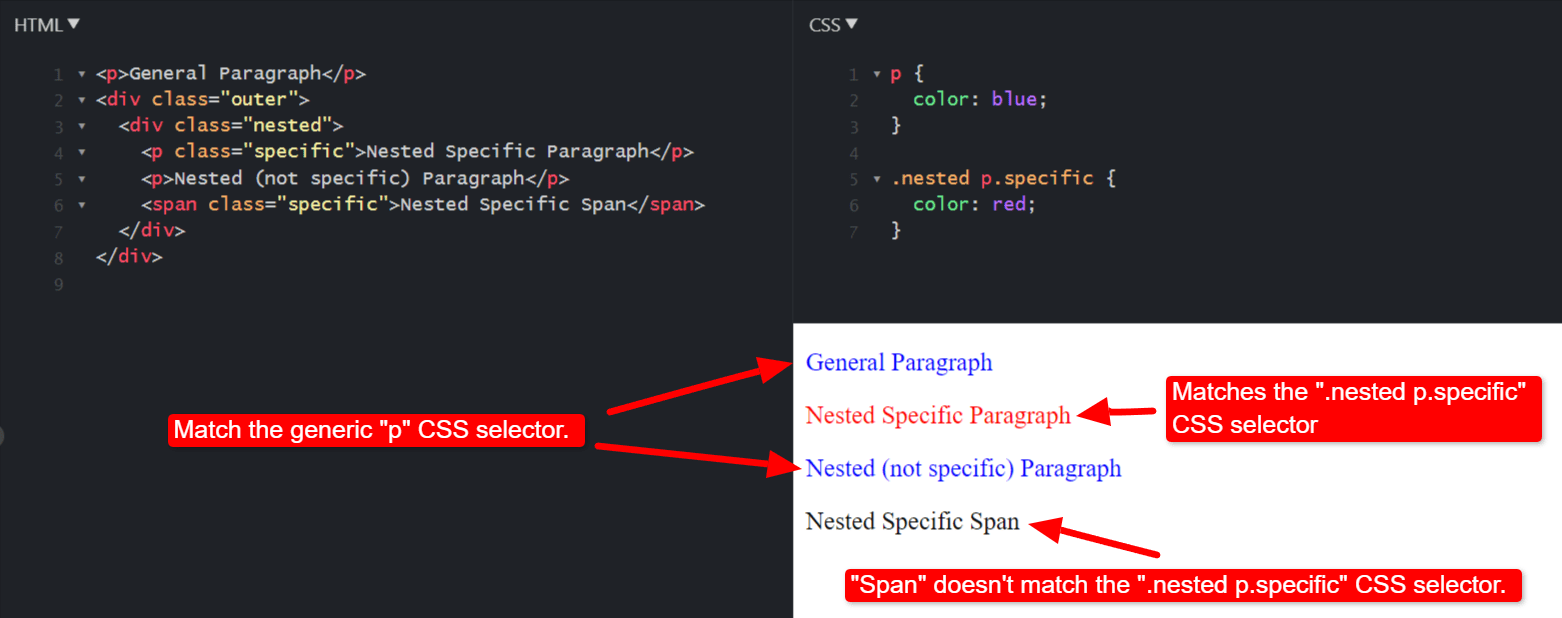
Advanced CSS selectorsusing class names and a nested structure.
jQuery introduced a robust and intuitive way for JavaScript programmers to access data on a web page by using CSS selectors. This paradigm has become the de facto standard for many toolkits that need to find specific data on a website, including the lxml Python toolkit.
Successful web scraping often depends largely on crafting complex CSS selectors to locate the specific data you want on that web page. This can often feel frustrating, especially for beginners. If you’re building your own web scraping tool but need help with advanced CSS selectors, you can buy HTML and CSS services from Fiverr freelancers to help you.
BeautifulSoup
Another powerful and popular Python library for parsing HTML is BeautifulSoup. The library doesn’t parse HTML but lets you plug other parser libraries into the tool. BeautifulSoup can even use lxml to parse HTML.
BeautifulSoup tends to be far more forgiving of poorly formatted HTML and has more support for detecting the encoding used in the page you’re trying to parse. Remember, correctly determining the encoding for the content you’re scraping is crucial to ensure you scrape the correct data.
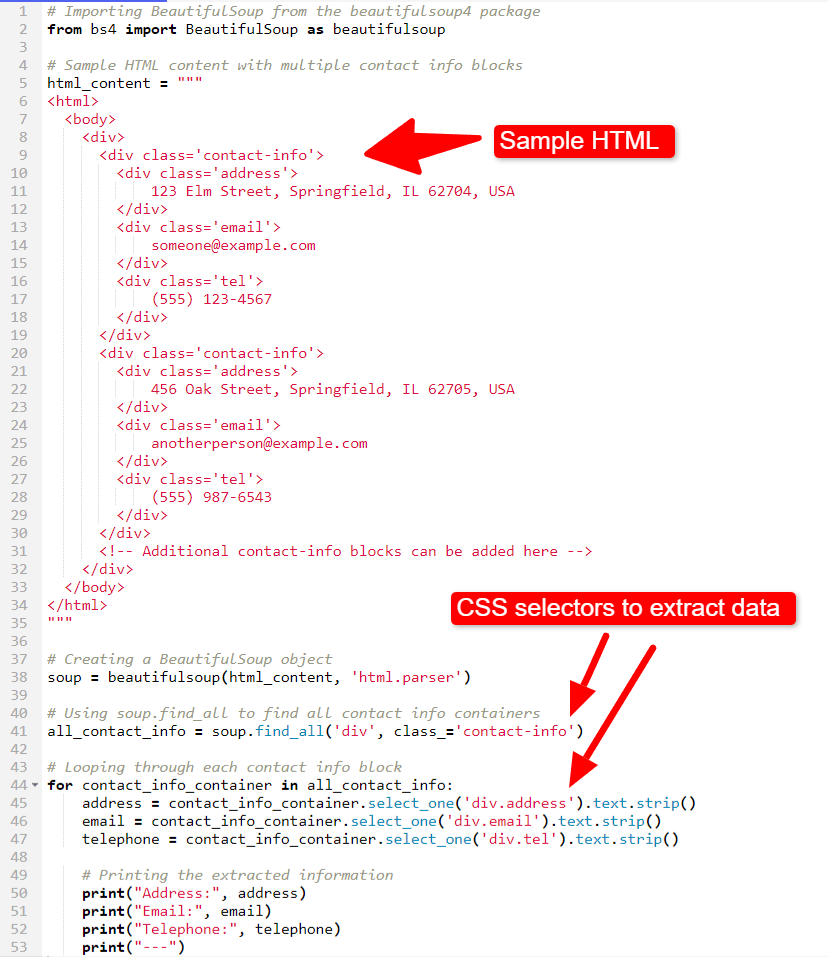
Python code sample showing how BeautifulSoup can parse HTML.
In the above code sample, we’re using sample HTML. For your Python web scraping tool, you’d wrap the BeautifulSoup code with HTTP requests and responses to fetch HTML from the web.
To use BeautifulSoup, import it from the beautifulsoup4 package using the name “bs4.”
from bs4 import BeautifulSoup as beautifulsoup
After that, create the BeautifulSoup object using the following line:
soup = beautifulsoup(html_content, ‘html.parser’)
We’ve specified Python’s native HTML parser when creating the BeautifulSoup object, but we can create it with any compatible parser, such as lxml:
soup = beautifulsoup(html_content, ‘lxml’)
In our sample HTML, we have a well-structured document with divs that contain class names for each “address” element. Using BeatifulSoup’s find_all method, we can easily create a collection of all the divs that match that CSS selector:
all_contact_info = soup.find_all(‘div’, class_=‘contact-info’)
Another method for selecting elements using CSS selectors is select. The find_all method’s syntax might feel more familiar to existing Python developers, while the select method uses a selector style that JavaScript developers might feel more at home with.
Here’s how to write the above code line using BeautifulSoup’s select method:
all_contact_info = soup.select(“div.contact-info”)
In our example, we print the content to the console. In a real-world example, you’d likely append the data to a growing data store of contact details.
It might not be possible to obtain perfect results for every record for highly complex web scraping tasks, where the HTML is extremely poorly formatted. In this case, it’s probably better to buy data cleaning services to fix any errors in the scraped data than to try to endlessly perfect the scraping tool.
Scraping JavaScript websites with Selenium
Many web pages today use JavaScript to render the HTML dynamically on the user’s browser. The response from the server contains basic HTML and the necessary JavaScript code to build further HTML directly in the browser.
The challenge is that the raw HTML from the server doesn’t necessarily contain the data you need until that HTML is rendered. Accessing the raw response from servers is fine for JSON and XML. For HTML that depends on JavaScript, however, you must first render the response in a browser.
Selenium is a powerful automation testing tool for testing websites. It works in the browser, rendering web pages, then executes code to carry out specific actions on that web page.
To get Selenium running, first install it using the following pip command:
pip install selenium
Using Python, you can now automate your preferred browser and scrape data from the web pages it loads. In your code, specify the web driver you want to use. In the code below, we’re using the Chrome web driver.
In the following rudimentary demo, we scrape a press release web page and print the results to the console. It’s simple to modify this code to run on a timer to monitor for any new press releases. You can buy Python programming services from Fiverr freelancers to help you do that.
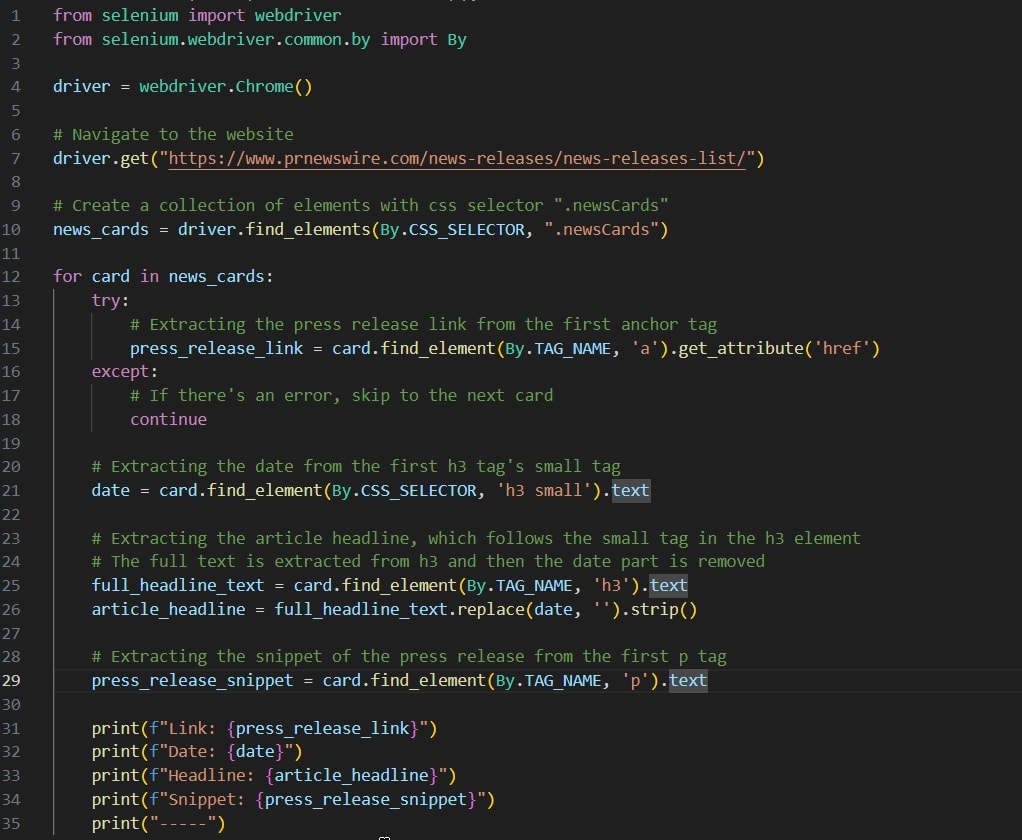
Selenium code sample to scrape press releases.
Advanced web scraping and crawling with Scrapy
If you want to create an extensive scraping solution that relies heavily on finding URLs and asynchronously loading them, Scrapy is a far better choice than the Python Requests library. Scrapy is a Python framework for crawling and scraping websites.
You can integrate BeautifulSoup and lxml into Scrapy to connect the power of these two libraries with the web crawling capabilities of Scrapy.
Hire Fiverr to build advanced Python web scrapers
The basics of web scraping are simple. You send requests and read responses. However, the responses might require running JavaScript or consist of poorly formatted HTML and XML. Additionally, the site you’re trying to scrape might contain protection mechanisms to block malicious users, which also end up catching your scraper.
Buying Python programming services from Fiverr is the best way to help overcome these challenges. When looking for a Python programmer to build a web scraping solution for you, it’s vital to ensure the programmer has experience in both web scraping and Python programming.
To find a programmer to help you develop your Python scraping solution, open an account on Fiverr and search for Python programmers. Alternatively, click on the categories in the top menu of the Fiverr website and look at the profiles in each category, then start a conversation to determine if they might be a match. You can buy programming services directly from the freelancer or ask them to send you a custom offer for your project.
To get started, open a Fiverr account today.
Hire an expert python programmer on Fiverr
Related Guides




About Author
R. Paulo Delgado Tech & Business Writer
R. Paulo Delgado is a tech and business freelance writer with nearly 17 years of software development experience under his belt, including WordPress programming. He is also a crypto journalist for Moneyweb, and proudly a member of Fiverr's Pro Seller program — hand-vetted professionals, verified by Fiverr for quality and service.
